Multimodal Interpretation
As machine learning models penetrate critical areas like medicine, the criminal justice system, and financial markets, the inability of humans to understand these models seems problematic. [1]
- Interpretability must be qualified. To be meaningful, any assertion regarding interpretability should fix a specific definition.
- Transparency may be at odds with the broader objectives of AI.
- 全局模型无关解释方法(Global Model-Agnostic)& 局部模型无关解释方法(Local Model-Agnostic)
Shapley Value
在合作博弈论中,是一种在合作的一组玩家之间公平分配总收益或成本的方法。例如,在每个成员贡献不同的团队项目中,Shapley Value提供了一种方法来确定每个成员应得到多少赞誉或责备。
例子:假设一个简化的企业生产环境,所有者
我们则有公司员工集合
假设价值函数
我们可以根据Shapley Value计算公式得到不同人的贡献:
Shapley Value计算公式
Game Theory for Economic Analysis. [1]
- 子集组合排序
- R的全排序
(示例)计算所有者贡献
令
SHAP-一种局部模型无关的可解释性方法
A Unified Approach to Interpreting Model Predictions [2]
https://shap.readthedocs.io/en/latest/
这里只提及了加权线性回归来近似计算(Kernel SHAP),还有深度学习网络 (Deep SHAP)
一种用于解释任何机器学习模型输出的博弈论方法。它利用博弈论中的经典 Shapley 值及其相关扩展,将最优信用分配(optimal credit allocation)与局部解释联系起来,即归因值。
归因值之和+基准值应该为预测值
**加性特征归因**三个特性
多个特征(或变量)的总贡献被认为是它们单独贡献的总和。
- 局部准确性 (Local Accuracy)
- 解释模型在简化输入 x′ 对应原始输入 x 时,至少匹配原始模型 f 的输出
- 所有特征的归因之和,精确等于模型输出与基线(背景分布均值)的差值。
- 可缺失性 (Missingness)
- 对于任何在所有上下文下都不改变模型输出的特征
,必须 - 即,如果模型并未“用到”这个特征,它就不应分到任何贡献。
- 对于任何在所有上下文下都不改变模型输出的特征
- 一致性 (Consistency)
- 若在另一个模型
中,对每一种上下文 ,若有 ,则应有
- 若在另一个模型
大部分方法,例如LIME、DeepLIFT只满足其中一两个特性,而传统Shaley Value估计方法能同时满足这三个特性。
- 归因值 φᵢ:确实是把特征 i 在所有可能的子集 S 中“加入”时对模型预测的边际提升累计起来。
- 模型预测:SHAP 中用的 v(S) 就是“在保留特征子集 S 值不变、其他特征随机化”下的条件期望。根据一个基准值
来计算。
- 加权平均:
- 每个边际贡献项
- 权重
在实际计算时,为了估计那个条件期望,往往会用背景样本做 Monte Carlo 近似,或者针对决策树用专门的 Tree SHAP 算法做精确计算。
Examples
Text

Image
import json |
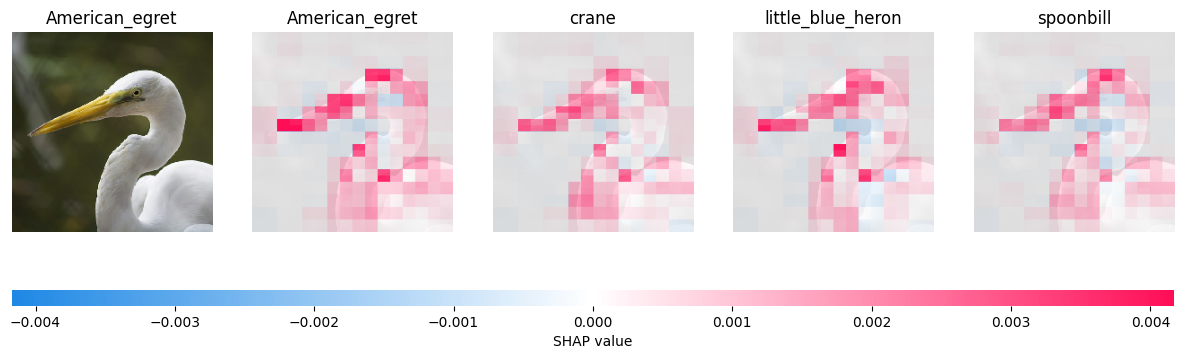
SHAP for MultiModal
刚刚的单模态SHAP里面有另外两个比较重要的特性
- 权重值和应为1
- 归因值之和+基准值应该为预测值
多模态与单模态的区别
单模态只处理单一类型的数据,如
- 文本(Text)
- 图像(Image)
- 语音(Audio)
- 结构化特征(Tabular)
而多模态同时处理**多种类型**的数据,比如:
- 图像 + 文本(如:图文检索、图像字幕生成)
- 语音 + 视频(如:视频理解、虚拟主播)
- 传感器信号 + 时间序列(如:多传感器融合的智能驾驶)
多模态模型架构与融合策略
- 早期融合(Early Fusion)
- 在最底层就把不同模态特征拼接/加权,送入统一网络
- “轻量级” CNN
- 特征维度极易爆炸,尤其当各模态维度都较高时会导致计算和存储压力很大;拼接后,网络往往无法区分哪些模式是“重要的”,容易引入大量冗余信息;
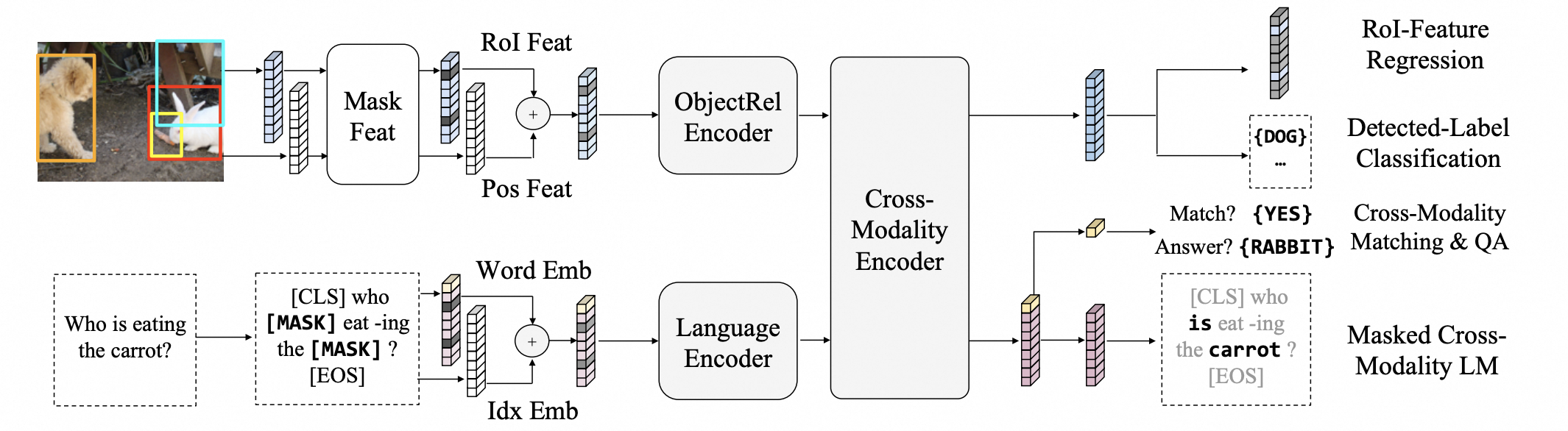
- 中期融合(Mid Fusion)
- 各模态先独立编码,再在中间层交互(如多头注意力跨模态)
- 例如LXMERT
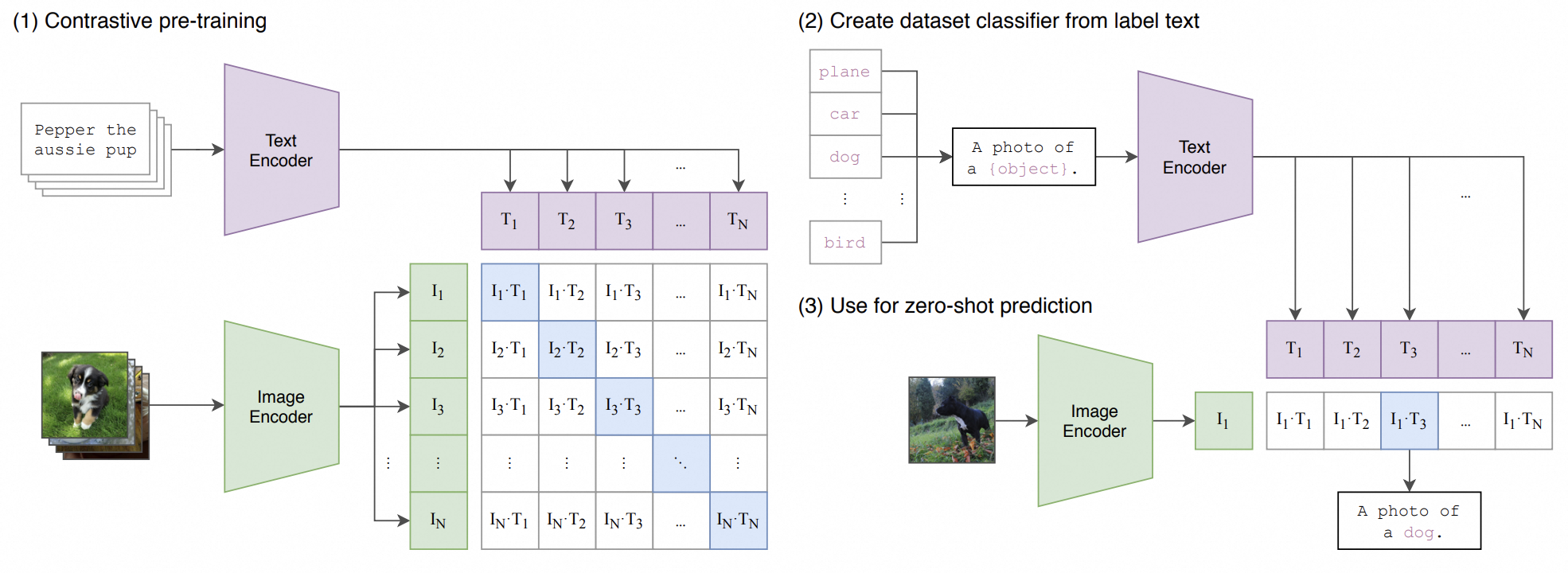
- 晚期融合(Late Fusion)
- 各模态单独预测,最后以投票或加权平均融合结果
- 例如 CLIP,图像和文本各自用独立编码器,映射到相同维度的嵌入空间,不在网络内部交互;最后通过相似度计算(如点积或余弦)来判断它们的关联性或并行输出多个任务的得分后再加权。
所以传统的SHAP没有办法解决
双模态下Shapley Value的推理
假定,图像特征为
对于图像特征
其中
而图像模态的价值(预测值)应为:
与此同时根据刚刚的权重计算方式(组合方式),而不是像单模态那样直接把特征值拉通:
为什么
需要+1,因为对于文本模态来说,图像模态可以看作是它的一个特征输入。
接着
如何使用SHAP来解释多模态
方案一
MM-SHAP: A performance-agnostic metric for measuring multimodal contributions in vision and language models & tasks [4]
- 对一条样本 (sentence,image_path)(\text{sentence},,\text{image_path})(sentence,image_path):
- 用 tokenizer 将句子转成
input_ids(长度为 L)。 - 用 FRCNN 抽取整张图像的 36 个 ROI 特征
features(形状 [1,36,d][1,36,d][1,36,d])和对应的normalized_boxes。
- 用 tokenizer 将句子转成
- 定义
custom_masker(mask, x)mask是长度为 L+36L 的布尔向量:前 L位用来控制文本 token,后 36 位用来控制图像 patch。
- 定义
predict - 初始化
SHAP Explainer - 对单条测试样本计算 SHAP 值
# ---------- 1. 准备:预处理函数和模型加载 ---------- |
方案二
- 把“文本看作一个整体”,把它当作一个超级输入,对比各个图像 patch 的边际贡献。
- 同理对图像再进行一次
- 合并到每个子输入的最终归因
延伸
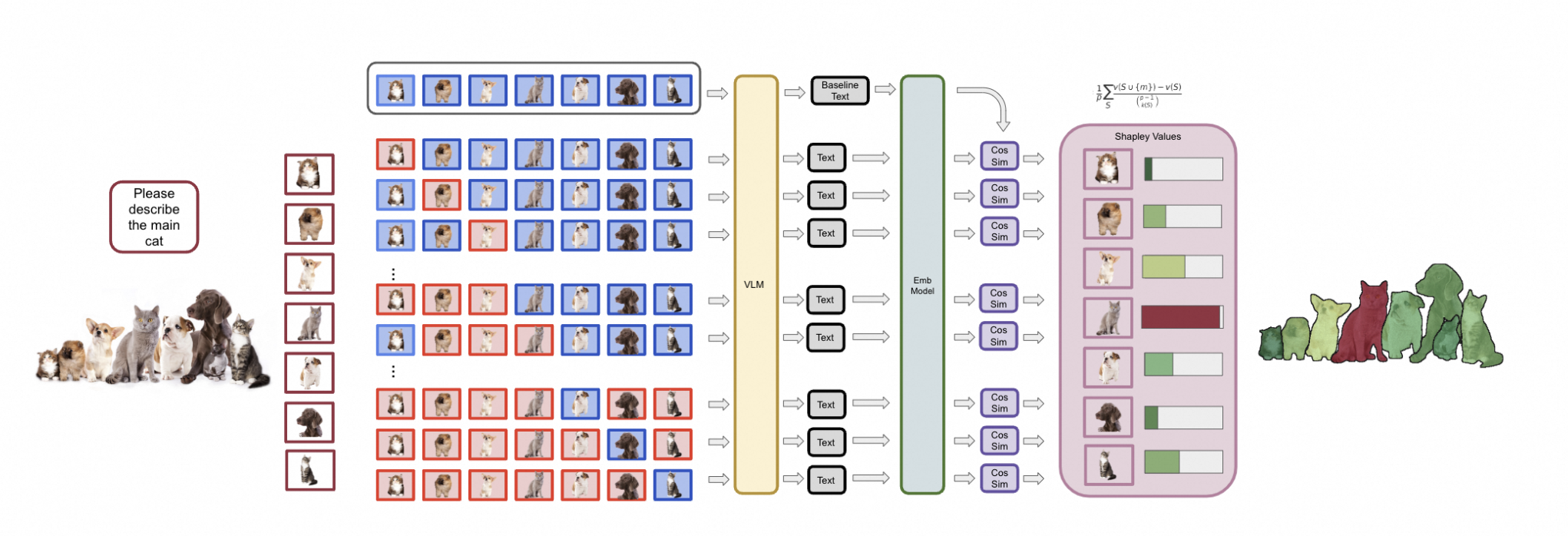
Attention, please! PixelSHAP reveals what vision-language models actually focus on. —— Roni Goldshmidt, 2025
- 通过 Mask R-CNN、SAM(Segment Anything Model)等分割算法生成候选对象或区域;
- 依次遮蔽单个对象(以基线贴图或随机噪声替换该区域),观察 VLM 重新生成文本的输出差异;
- 根据 Shapley 公式集成这些差异,得到每个“图像对象”对文本输出的贡献评分。
References
[1]. Lipton, Z. C. (2016). The mythos of model interpretability. arXiv preprint arXiv:1606.03490. https://doi.org/10.48550/arXiv.1606.03490
[2]. For a proof of unique existence, see Ichiishi, Tatsuro (1983). Game Theory for Economic Analysis. New York: Academic Press. pp. 118–120. ISBN 0-12-370180-5.
[3]. Lundberg, S. M., & Lee, S.-I. (2017). A unified approach to interpreting model predictions. In I. Guyon et al. (Eds.), Advances in Neural Information Processing Systems, 30, 4765–4774. Curran Associates, Inc.
[4]. Parcalabescu, L., & Frank, A. (2023). MM-SHAP: A performance-agnostic metric for measuring multimodal contributions in vision and language models & tasks. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL ’23) (pp. 4032–4059). Association for Computational Linguistics.
[5]. Lipovetsky, S., & Conklin, M. (2001). Analysis of regression in game theory approach. Applied Stochastic Models in Business and Industry, 17(4), 319–330.
[6]. Goldshmidt, R. (2025). Attention, Please! PixelSHAP Reveals What Vision-Language Models Actually Focus On. arXiv preprint arXiv:2503.06670.
[7]. Horovicz, M., & Goldshmidt, R. (2024, July 14). TokenSHAP: Interpreting large language models with Monte Carlo Shapley value estimation. arXiv preprint arXiv:2407.10114.
- Title: Multimodal Interpretation
- Author: Hao Feng
- Created at : 2025-06-15 20:02:43
- Updated at : 2025-08-14 09:22:27
- Link: https://matt23-star.github.io/2025/06/Multimodal_Interpretation/
- License: This work is licensed under CC BY-NC-SA 4.0.